
by Markus Breuer | Sep 20, 2022 | Software Architecture
Heard about Architecture Decision Records? Anyone who moves to a new team quickly faces familiar questions. Why did colleagues solve the problem in this way? Did they not see the consequences? The other approach would have offered many advantages. Or did they see...
by Markus Breuer | Sep 4, 2022 | Software Architecture
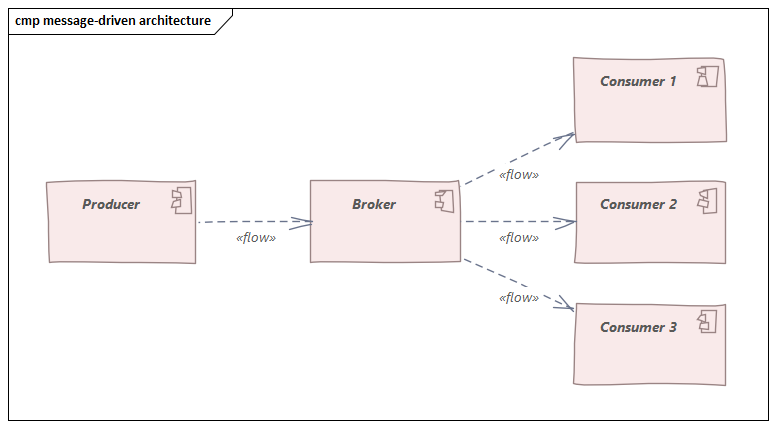
What is event-driven architecture? What are the advantages of event-driven architecture, and when should I use it? What advantages does it offer, and what price do I pay? In the following, we will look at what constitutes an event-driven architecture and how it...
by Markus Breuer | Aug 14, 2022 | Big Data, Software Architecture
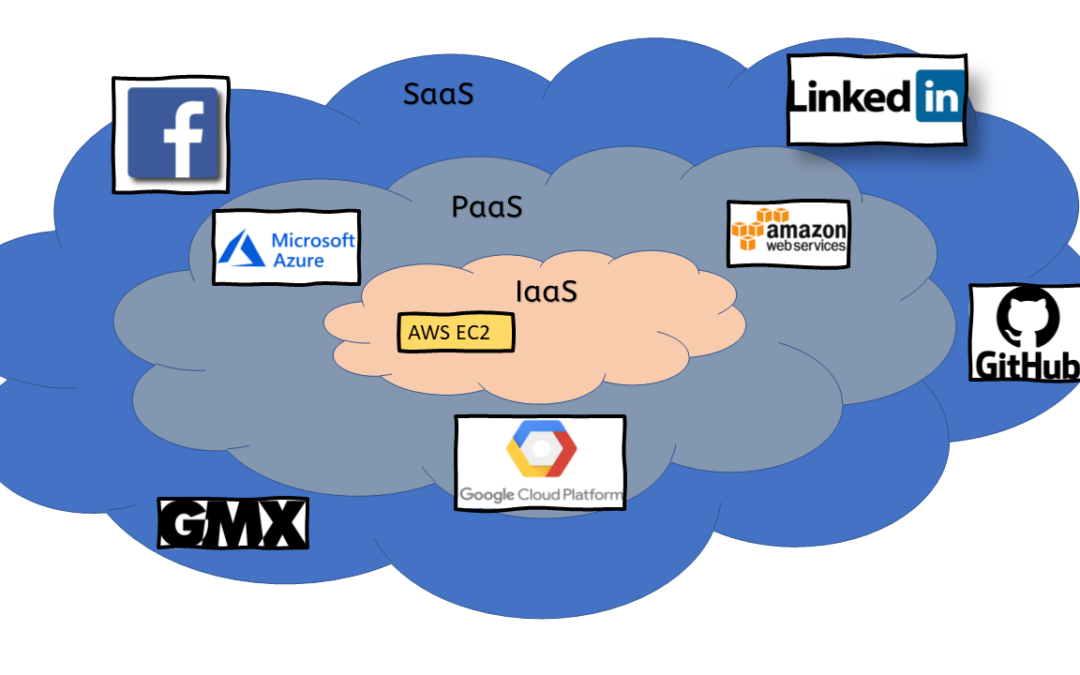
What does it mean to run an application in the cloud? What types of clouds are there, and what responsibilities can they take away from me? Or conversely, what does it mean not to go to the cloud? To clarify these questions, we first need to identify the...

by Markus Breuer | Aug 5, 2020 | Big Data
Regular Expressions are a powerful tool to split texts into fragments. Furthermore, Apache Spark is an analytics engine and capable of processing large amounts of data sets. The feature of naming capturing groups makes the usage of regular expressions more accessible....

by Markus Breuer | Jul 25, 2023 | Software Architecture
Introduction The principle of abstraction is a fundamental concept in software development that helps simplify complex systems by hiding unnecessary details. In this article, we will explore the significance of abstraction, its benefits, and how it impacts software...

by Markus Breuer | Jul 25, 2023 | Software Architecture
Introduction The principle of loose coupling plays a crucial role in software development by minimizing dependencies between components. This article will explore the significance of loose coupling, its benefits, and how it impacts software development. Understanding...

by Markus Breuer | Jul 25, 2023 | Software Architecture
Introduction The principle of cohesion is essential in software development, focusing on creating highly cohesive and self-contained modules or components. In this article, we will explore the significance of cohesion, its benefits, and how it influences software...

by Markus Breuer | Jul 25, 2023 | Software Architecture
Introduction The principle of separation of concerns is a fundamental concept in software architecture. It emphasizes dividing a system into distinct parts, each responsible for a specific aspect or matter. This approach promotes modularity, maintainability, and...

by Markus Breuer | Jul 25, 2023 | Software Architecture
Introduction The principle of modularity drives software architecture by promoting flexibility, reusability, and efficient development. In this article, we explore the significance of modularity, its benefits, and its impact on software development. Understanding...
by Markus Breuer | Oct 24, 2022 | Software Architecture
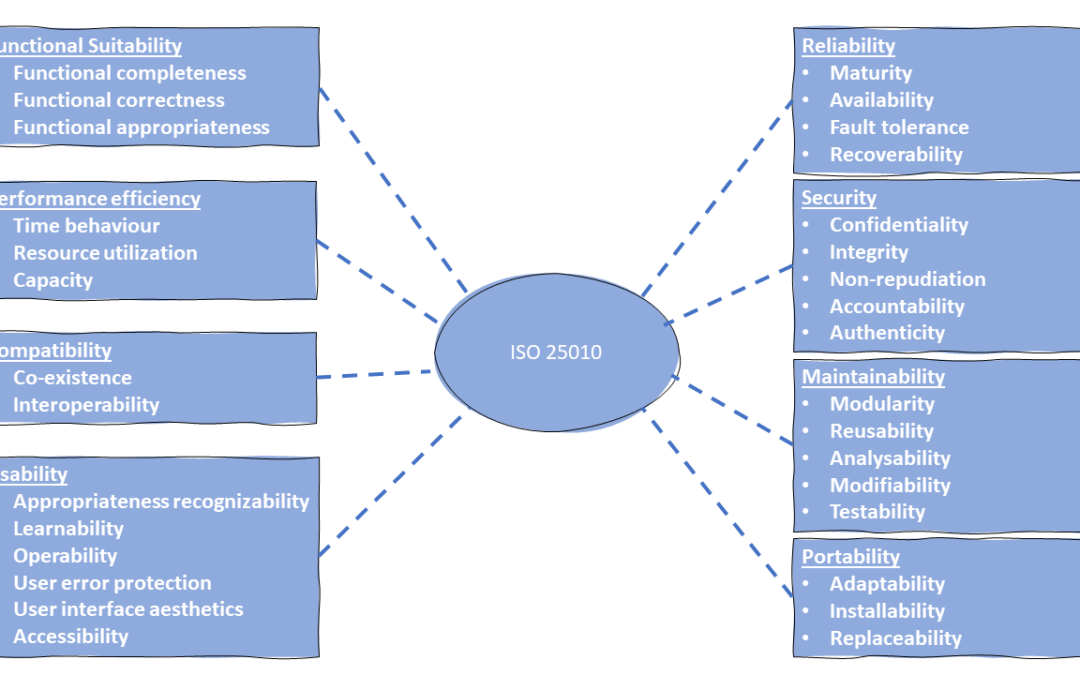
Ever heard about quality scenarios? We are completing the development and delivering the software to the customer. But the customer is disappointed and describes the software as poor. The developers believe that they have complied with all the requirements....

by Markus Breuer | Sep 25, 2022 | Software Architecture
Have you ever heard the term Service Discovery and wondered what it means? This article explains what is meant by the term service discovery in the context of software architectures. Definition of Service Discovery Service discovery is the automatic discovery of...
Recent Comments