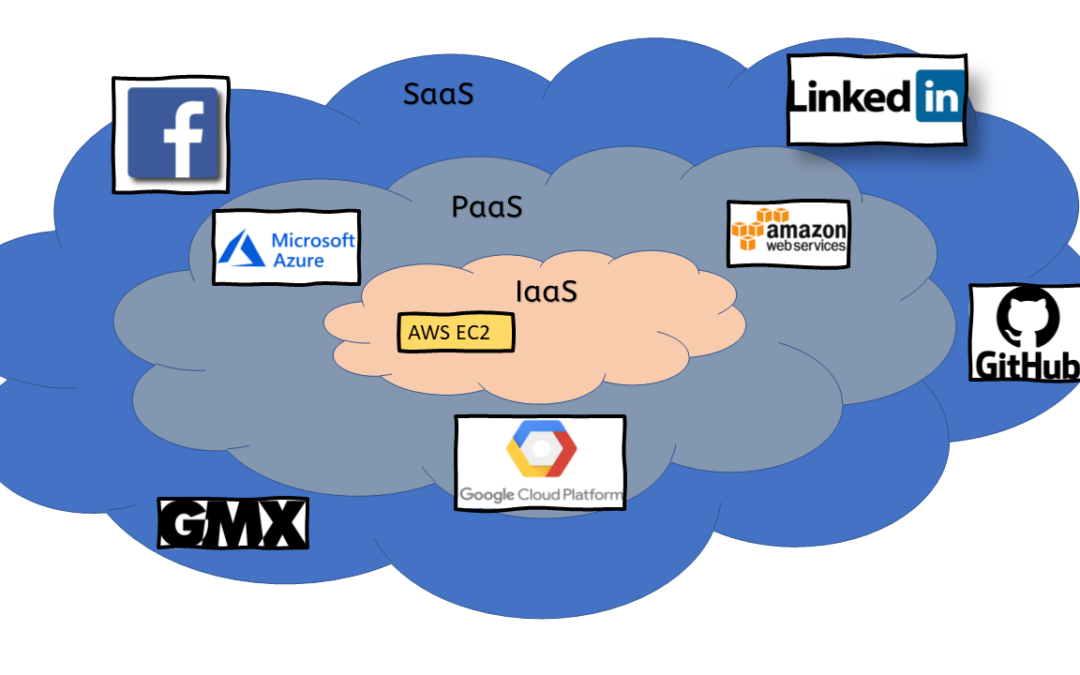
by Markus Breuer | Aug 14, 2022 | Big Data, Software Architecture
What does it mean to run an application in the cloud? What types of clouds are there, and what responsibilities can they take away from me? Or conversely, what does it mean not to go to the cloud? To clarify these questions, we first need to identify the...

by Markus Breuer | Jun 11, 2022 | Big Data
Here are some Apache Spark and Delta Lake examples. Actually, they are always the same problems. But searching and finding the solutions on the internet costs a lot of time. Is something still missing? Then just let me know! Preparations The Apache Spark distribution...

by Markus Breuer | Jun 7, 2022 | Big Data
Running Apache Spark from the Docker image causes problems with autocomplete in the shell. In that way, the apache spark-shell autocomplete is broken. Suspicion falls on the terminal settings and the JLine configuration. In fact, the cause lies in a completely...

by Markus Breuer | Aug 7, 2021 | Big Data
A list of common Docker Topics (more): The Haskell Dockerfile Linter helps to build best practice Docker images. The Dockerfile Lint allows the building of custom policies to build best practice Docker images. Use Makefiles for Docker building Docker Images. How...

by Markus Breuer | Aug 5, 2020 | Big Data
Regular Expressions are a powerful tool to split texts into fragments. Furthermore, Apache Spark is an analytics engine and capable of processing large amounts of data sets. The feature of naming capturing groups makes the usage of regular expressions more accessible....
by Markus Breuer | Dec 15, 2019 | Big Data
Openshift offers many possibilities to embed files in pods. Furthermore, there are many reasons to include files in pods. So, embedding configuration files is a powerful mechanism. In this way, unchangeable containers become populated with dynamic content. In brief,...
Recent Comments